Web-First Data Citations
| License | CC-BY-SA 4.0 |
|---|
Abstract
We identify a set of properties desirable in a concrete implementation of data citations, considering the full publishing pipeline as well as the needs of landing pages for datasets. Building on top of these properties, we describe the specific implementation approach that we take, built completely on top of Web standards. Web technology is found once again to be awesome and more versatile than people expect.
Introduction
The need for data citations has been a discussion topic across disciplines for at least two decades (Sieber and Trumbo 1995) and longer in specific fields, but in recent years progress has been made describing the problem space (CODATA-ICSTI Task Group on Data Citation Standards and Practice 2013) and towards broad consensus concerning the principles guiding the deployment of data citations (Data Citation Synthesis Group 2014).
On the implementation front we can now benefit from the experience of many parties, not solely from the scholarly universe such as data repositories, researchers, or publishers, but also from the broader community of practice in modern publishing technology. However, converting experience into shared standards still requires pragmatic efforts, and if there is some degree of convergence towards a solution space (Starr et al. 2015) much remains to be done.
We proceed by listing the desirable and undesirable technical properties of existing or potential solutions. Building on that characterization, we then outline a technological approach to data citations.
Method
The list of aspects presented in this section was not produced systematically, rather it stems from reviewing the problem space, various potential solutions, and the salient features of the approach we have taken. Our intent is to keep the discussion pragmatically focused on areas likely to require decisions, rather than exhaust the full breadth of technological solutions that can be envisaged for the problem at hand.
Choice of Ontology
The general list of information considered good practice for data citations is well-defined and very reasonably constrained (Starr et al. 2015). Translating that into a concrete implementation does however require choosing an ontology to match it. There are three possible high-level approaches:
Create an ad hoc ontology precisely matching the requirements.
Use an ontology (or several) created specifically to address the domain.
Use an ontology (or several) designed with broader applicability in mind (but known to possess sufficient descriptive capability).
Option (1) of an ad hoc solution would be useful if either no existing alternative were available, or if it were a requirement that the metadata system be closed (i.e. no property beyond the required set may be captured). Neither of these is the case, therefore we can rule it out.
Choosing between domain-specific and general-purpose solutions is less immediately obvious. A common temptation is to expect the more specific solution to be a better fit, but that may not be systematically the case and looking at a variety of properties that ontologies may have is required to make an informed decision. The properties that we considered in order to make our decision include:
Expressiveness
Different ontologies will describe the world at different levels of granularity. While the simplest possible ontology (in which everything is a “thing”) is obviously of limited use, this does not entail that increasing granularity is always preferable: having as separate classes documents with 5,357 characters, documents with 5,358 characters, etc. would not be much more useful, very much like a monetary system in which there would be distinct bank note denominations for every possible transaction price. The most important questions to ask where expressiveness is concerned is whether a given ontology can capture the expressed requirements correctly (possibly with a few additional “nice-to-haves”) and whether it appears to be extensible for potential future usage.
Complexity
In order for an ontology to be useful, it needs to be understandable by a variety of actors. These include at a minimum the information creators, its consumers, and the implementers of tools to process it.
While too low a complexity may stifle expressiveness, there are direct costs involved in increasing ontological complexity. Beyond a certain level, the errors made by producers (who only have so much time to understand the finer distinction between classes) increase in rate to the point where the distinctions have to be considered as irrelevant in order to process the information. Where implementations are concerned, increasingly the complexity directly increases the cost of software used to produce and process the data, a cost that tends to translate into lower-quality tooling and that furthermore continues over time as software needs to be maintained.
Given an intricate, multifaceted world, imprecision can prove an asset.
Specific metrics of ontological complexity are beyond the scope of this paper, but as a rule of thumb implementation-driven ontologies — which are developed in response to the use cases of tools consuming it — tend to be much simpler than modelling-driven ontologies, which encode the worldview of domain specialists who might not have usability in mind.
Adoption
An ontology’s value is derived in large part from the degree to which it is shared. A direct comparison may be drawn with the usage of jargon within a discipline: there is no doubt that precise, technical terminology is greatly helpful in conveying some ideas, but cases in which it has been taken too far abound.
Given comparable expressiveness, a domain-specific ontology (even if the domain is as broad as scholarly publishing) will be much less valuable in that it will have far fewer speakers able to usefully process it than an ontology operating at the full scale of the Web.
Greater adoption also helps with greater persistence — and if the persistence of metadata is to be guaranteed, that is transitively the case for its ontology too.
Tooling & Documentation
It is not sufficient to define a set of classes and properties; without implementation they are but fiction. While tooling and user resources can be developed over time, believing that they will naturally come is often wishful. The world of standards is littered with dead dreams; a solution that has already shown itself as benefitting from the support of tools, writing, and a community of practice will tend to be a surer bet.
Wide review
Like every other product of the human mind, and as is well documented in the history of philosophy, ontologies have bugs. They can miss essential concepts or make them awkward to express, they can lead to contradictions, or even have simpler issues such as typos that nevertheless can get in the way. Many of these issues will only surface after the ontology has actually been used in earnest, preferably not by those who designed it.
Given a choice, an ontology that has benefitted from broad attention and review, and several debugging iterations, will be preferable.
Formats: Source, Publication, Archival
Once an ontology has been selected, a common format in which to encode it (in view of supporting both citations and landing pages) needs to be selected. Describing the properties most desirable in a format for scholarly articles in general is too broad a topic for the issue that concerns us here, but given that data citations will find themselves embedded in scholarly articles it is worth considering the intersection of the two.
The first thing to note is that the properties used to assess an ontology’s value apply overall equally well to formats. We will therefore not revisit them.
The present situation in scholarly formats is scattered between source authoring formats (often Word or to a lesser degree LaTeX), “backend” formats (typically JATS or a comparable XML-based variant), and online publication formats (HTML and PDF). In the short term, these need to be addressed separately.
Today's common authoring formats are by and large hopeless but consideration should be given to supporting conventions they can express so as to facilitate automated information extraction.
JATS (and generally XML formats) should not present a particular challenge. The existing means of capturing citations can be extended to convey the specificities of data citation, as exemplified in (Lapeyre 2015).
PDF is predominantly an image format and not suitable for information encoding. RDF can be included using XMP (https://en.wikipedia.org/wiki/Extensible_Metadata_Platform) but it is probably more realistic to treat it as a dead end.
HTML however presents a particularly interesting case that warrants closer attention. While the scholarly world has often treated it as a second-class “output” format tolerated as what the search engines index so that users may get to the PDF, the language has evolved to the point where this attitude could benefit from being revisited.
More recent standards such as RDFa make it possible to embed rich semantics directly in HTML. These enable HTML documents to capture arbitrary content while still being directly publishable on the Web, stylable, scriptable, etc. This makes HTML a general-purpose markup technology with which domain-specific vernaculars can be produced while remaining immediately processable by an extremely rich ecosystem of tools, many of which are directly in the hands of end-users (browsers, search engines…).
With this in mind, looking towards HTML as a first-class citizen in which the full expressiveness of the selected ontology need be captured becomes a valuable goal.
Embedding versus Splitting
Several proposed solutions (for instance (Starr et al. 2015) but not only) suggest serving the metadata of a landing page (and presumably of articles in which citations occur) separately from the body of the HTML document sent to browsers, through means such as HTTP Content Negotiation (in which the server sends different content depending on what the client declares it can accept) or Web Linking (in which an HTTP header is used to indicate the presence of a related resource).
We plainly and simply rule out such options. To begin with, they are not in any way, manner, or form needed in order to address the use case of obtaining the information in machine-actionable form. HTML has the means to embed strictly equivalent content, making it possible to cater to both humans and machines with a single implementation.
Additionally, they suffer from serious drawbacks. They require more specific work on the server side whereas HTML-embedded metadata can be served using off-the-shelf servers. They are simply ignored by search engines, whereas the latter today make extensive use of rich HTML data in order to improve both their search results and the user experience (for instance through “rich snippets” that come embedded with search results). Discoverability suffers directly as a consequence of splitting that information out.
General-purpose archiving systems that crawl the Web to maintain its memory also routinely ignore split-out content but keep the full HTML; a fact that has a direct impact on persistence.
Furthermore, splitting up the data has an impact on its quality. A single channel used by both humans and machines combines their different abilities to detect issues whereas splintered approaches can go out of sync or suffer from translational errors leading to multiple versions of the truth.
The metadata embedded in HTML can be used as a target for styling through CSS, increasing the odds that if the metadata is wrong it will also look wrong to human readers, even without looking at the source. At the scale of a publisher or repository, this can lead to discovering issues that would otherwise go unreported. To give a concrete example, we have routinely encountered metadata about scholarly articles featuring one { “givenName”: “Et”, “familyName”: “Al” } as one of the authors (and a most prolific one at that). Since the CSS styling is targeting the semantic information containing the document, such occurrences look wrong (rendered as people) even on casual inspection.
Noticing numerous architectural downsides and no upside to speak of, the split out approach seems to us needless.
Long-Term Persistence
In (NRC 2012) Michael Sperberg-McQueen conveys welcome caution:
Our current citation practice may be 400 years old. The http scheme, by comparison, is about 19 years old. It is a long reach to assume, as some do, that http URLs are an adequate mechanism for all citations of digital (and non-digital!) objects. It is not unreasonable for scholars to be skeptical of the use of URLs to cite data of any long-term significance, even if they are interested in citing the data resources they use.
— Michael Sperberg-McQueen, “Data Citation in the Humanities: What’s the Problem?”
Things have improved since Michael’s intervention: last year the Web celebrated its 25th birthday. Taking the long view, however, he is certainly right that we should not be naïve as to the longevity of the solutions we have today. Conversely, we should not wait for some perhaps forthcoming perfect long-term storage system guaranteed to survive civilisational collapse: had the first scholarly journals done so, they would be yet to exist.
We can nevertheless build robustness into the manner in which we deploy the solutions available to us. HTTP, HTML, and many others may not be forever, but we can apply them so as to ensure the resilience of their content in the face of change. This can be achieved through the application of several principles, at both ends of the citation system (source and landing page).
First, we must ensure the discoverability of this information. For this using links that function on the Web works, as does embedding the information where it is most likely to be archived and indexed.
Second, we can make use of organic persistence. If the metadata is not just embedded but also redundant such that we do not have simply an identifier or URL but also the title, authors, etc. then should the URL or identifier system eventually fail, the content stands a chance of being rediscovered.
The more common and widely used the solutions we rely on, the more likely they are to remain usable in the farther future. While insufficient to meet the demands of professional long-term archivists, applying well-documented, open, widely deployed standards increases the survival chances of information — especially if said information does not reach the capable hands of archivists.
Versioning
Datasets are prone to evolving over time, far more so than peer-reviewed articles. Knowing which changes are likely to affect reproducibility can be difficult and requires coordination between both ends of the citation. Fixing a small number of erroneous values in a large dataset may have a minimal impact on some aggregate computation while it could throw highly-sensitive processing into a completely different state. Changing a column’s name without touching the data might break code used to analyse them, even if the analysis remains just as valid.
It is possible to take the very strict view that one should only ever cite a single, frozen, static version of a dataset, and indeed it is likely that such a practice will be considered preferable by some authors, journals, societies, or even disciplines. However, one can equally well imagine that researchers may wish to convey their confidence that their analysis is resilient to relatively minor variations in data — such a statement is stronger, and it shouldn’t be surprising to see some domains grant greater credence to results not tied to the specificities of a static dataset.
Similar debates have agitated the software world (about whether dependencies should be “vendored” or “nailed down”, or on the contrary given some flexibility) and the standards world (about whether a standard should solely reference other stable standards, or if they should be produced with orthogonality sufficient to guarantee their resilience to change).
In the open source world, this situation has been addressed on one side by providing a software author with the means to signal the degree to which a given release affects the previous release through “Semantic Versioning” (Preston-Werner 2014), and on the referring side to give authors the responsibility to express how deeply coupled they believe their code to be to their dependencies (npm 2015).
Our approach here is to consider that it is not the standard-makers’ job to prescribe which practice is best for all disciplines, but rather to establish simple but effective means for each domain to choose its own preferred approach (while retaining global interoperability).
Extensibility
As a general rule, any implementation of the core set of data citation requirements should be known to be extensible so that not only can it be improved across the board in the future but also so that specific disciplines are immediately able to enhance it with additional information relevant to their specific needs.
Discussion
The method above is described through the lens of data citations, but in a broader manner largely matches that which motivates the choices made in “Scholarly HTML” (Berjon and Ballesteros 2015). Building atop our existing implementation experience bolsters our confidence in the solution we outline.
Ontology
The ontology we rely upon in order to describe data citations (and in fact almost all article-related metadata) is schema.org (schema.org 2015). This choice was made because not only does it rate very high on the criteria listed above, but it also brings additional benefits all of its own.
It has benefitted from extremely wide review, having been through several dozen releases, which are managed through a public GitHub repository that has seen hundreds of issues raised and addressed by the community. Exact adoption numbers are not published at this time, but the site does provide orders of magnitude of usage for classes and properties, with several reaching into the millions. Reliable (but anonymous) personal communication reported usage of schema.org at over seven million domains in November 2014.
Where tooling and documentation are concerned, schema.org benefits not just from the official Web site (which is already a great resource for users) but also from several other sites offered by the community or by companies that use it to provide examples of usage, validators, or tools to see how a given piece of markup is being interpreted by its consumers. Its semantics are understood by large, general-purpose search engines such as Google or Bing, which use it to improve their results and to include interactive snippers, as well as by email clients such as Gmail where embedded schema.org serves to render emails interactive.
The schema.org vocabulary is more than enough to capture the requirements for data citations (as shown in Code 1 below). Of particular note, schema.org’s notion of “Roles” makes it possible to capture rich semantics by combining existing blocks. If schema.org’s breadth as a vocabulary may raise concerns as to its complexity, in practice its modelling is such that one only needs to be concerned with a small subset in order to carry out a given task. Its broad usage by Web developers with no training in ontology or data modelling speaks for its simplicity.
{
"@context": "https://science.ai/",
"@id": "doi:10.4242/cryptoZ.2017",
"@type": "Dataset",
"isBasedOn": {
"@type": "DependencyRole",
"isBasedOn": {
"@type": "DataDownload",
"contentUrl": "http://berjon.com/cz",
"name": "Sightings of Levrogyrous Dahuts during…"
},
"matchVersion": "^1.1.0",
"fileFormat": "text/csv"
},
"author": {
"@type": "Person",
"givenName": "Robin",
"familyName": "Berjon"
},
"datePublished": {
"@type": "xsd:gYear",
"@value": "2015"
},
"publisher": {
"@type": "Organization",
"name": "Cryptozoology International",
"location": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressLocality": "Grenoble",
"addressCountry": "France"
}
}
},
"potentialAction": {
"@type": "ReadAction",
"actionStatus": "CompletedActionStatus",
"datePublished": {
"@type": "xsd:date",
"@value": "2015-10-15"
}
}
}JSON-LD representation of a data citation
Format
Having availed ourselves of a powerful data model accurately describing data citations in a general manner, we turn to its encoding in actual data formats.
It is relatively simple to define a bi-directional mapping between that data model and for instance the proposed implementation of data citations in JATS put forth in (Lapeyre 2015), as well as to other XML vocabularies. However, given that schema.org is designed to operate natively on the Web we are naturally drawn to produce an HTML encoding for it, as shown in Code 2.
<div typeof="schema:Dataset"
resource="doi:10.4242/cryptoZ.2017">
<span property="schema:isBasedOn"
typeof="schema:DependencyRole">
<span property="schema:isBasedOn"
typeof="schema:DataDownload">
<a href=http://berjon.com/cz
property="schema:contentUrl">
<cite property="schema:name">
Sightings of Levrogyrous Dahuts during Transalpine
Migratory Periods
</cite>
</a>
</span>
<span property="schema:matchVersion">^1.1.0</span>
<span property="schema:fileFormat">text/csv</span>
</span>
by
<span property="schema:author" typeof="schema:Person">
<span property="schema:givenName">Robin</span>
<span property="schema:familyName">Berjon</span>
</span>.
Published in
<time property="schema:datePublished"
datatype="xsd:gYear" datetime="2015">2015</time>
by
<span property="schema:publisher"
typeof="schema:Organization">
<span property="schema:name">Cryptozoology
International</span>
(<span property="schema:location" typeof="schema:Place">
<span property="schema:address"
typeof="schema:PostalAddress">
<span
property="schema:addressLocality">Grenoble</span>,
<span property="schema:addressCountry">France</span>
</span>
</span>)
</span>.
Accessed on
<span property="schema:potentialAction"
typeof="schema:ReadAction">
<meta property="schema:actionStatus"
content="CompletedActionStatus">
<time property="schema:datePublished"datatype="xsd:date"
datetime="2015-10-15">15 Oct 2015</time>
</span>.
</div>A data citation fully captured in HTML
As can be seen in the example above, we make use of HTML’s extensibility in order to enmesh complex semantics in a body of text, making our content accessible to both machines and humans. Machines will see an internal representation of the data graph shown below in Figure 1.
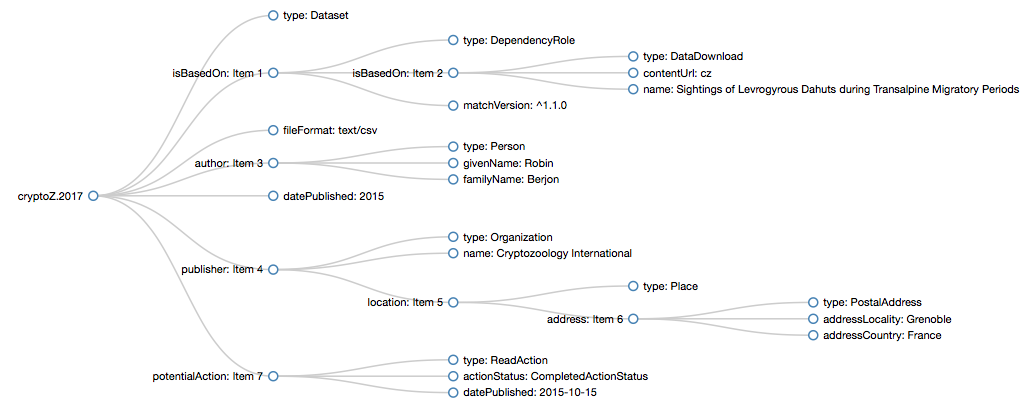
A graph representation of the data citation metadata

Example rendition of a data citation
Ultimately, the ability of HTML to express the full content of a data citation — in fact the full data and metadata of a scholarly article — leads us to the conclusion that HTML can serve as the primary format of the publishing tool-chain, using the exact same document for the production process, online publishing, print publishing (through the application of a print-oriented style sheet), and long-term archival.
This method has several advantages. It eliminates the bugs involved in the translation between formats for the purpose of publishing. It also exposes the full richness of a publisher’s information for consumption by third-parties instead of an impoverished, downgraded subset. It greatly improves the indexing of the content both by general-purpose and specialised search engines, and enables rich snippets in search results as shown below in Figure 3. These greatly improve the search experience for end-users.
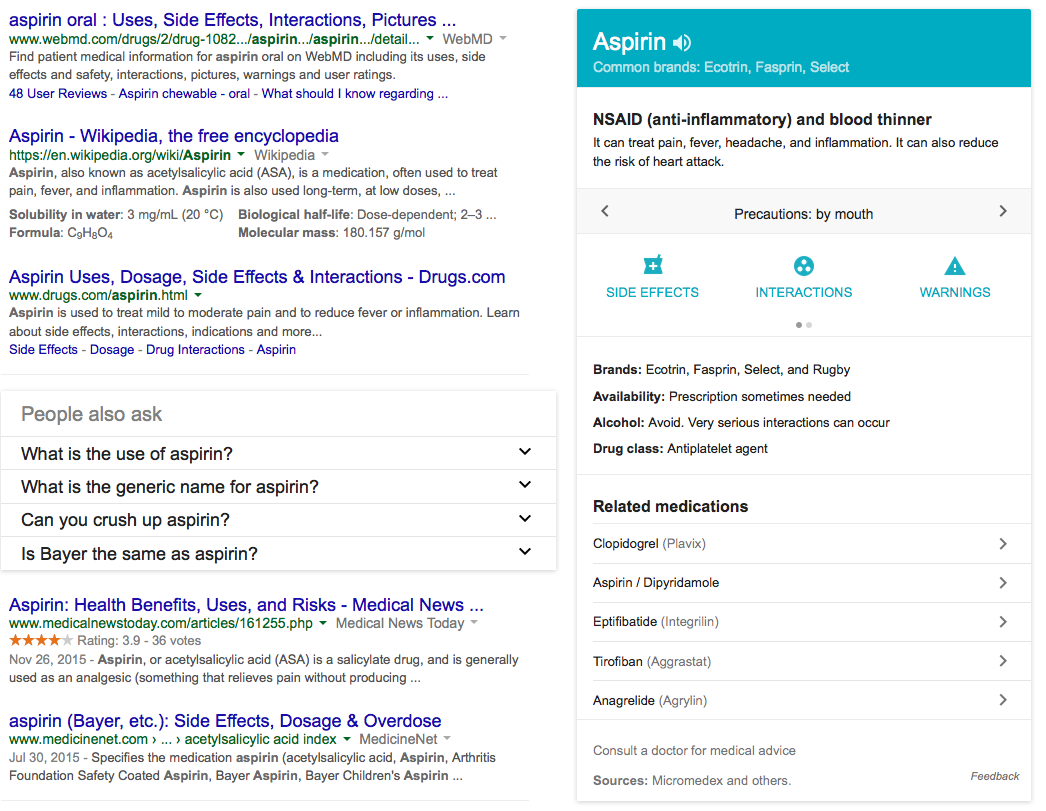
Rich snippet for "aspirin"
It is worth noting that using HTML as a first-class citizen in scholarly publishing means that practically the same markup can be used both for the citation and the landing page describing a dataset. This opens the door to improved data quality in citation services as well as to the ability to automatically check the correctness of a given citation.
The only part of the publishing pipeline that HTML does not (yet) address well is authoring. Current general-purpose HTML editors are no worse than the likes of Microsoft Word, but are not any better either.
It is, however, possible to make use of a simple set of guidelines — essentially a standardised style guide — in order to support the automatic extraction of complex metadata from Word documents. This is essentially what we have done with the “DOCX Standard Scientific Style”, colloquially known as “DS3” (Bogich and Ballesteros 2015).
The DS3 approach is designed to work well with Word, but it does not make use of any advanced Word-specific tooling, and therefore ought to be extensible to other authoring formats. We simply worked on Word first as it massively dominates the authoring landscape (101 Innovations 2015).
The data model we have chosen and the formats that support it can in fact work if the metadata is published separately from the document in which it occurs (be it an article or landing page, or in fact any other type of document), for instance in JSON-LD or using any other RDF serialisation. However, in addition to the advantages of the embedded version listed in the Embedding versus Splitting section it is worth noting that the embedded metadata makes it possible to style the output using CSS with no further modification of the markup (i.e. without the addition of classes or identifiers). The rendering shown in Figure 2 is obtained in just such a manner. This greatly enhances the interoperability of the content since the markup does not need to be modified in order to fit into the specific presentational needs of a given publisher.
Persistence
In the vast majority of cases, the HTML as published on the Web is what third-parties will spider and archive in their own systems. Making the document published to the Web semantically self-contained (again, be it for articles citing data or for data landing pages) grants the published information far greater organic persistence. While it is no match for a full-fledged long-term archival system, it nevertheless contributes to the resilience of the system, even in the face of institutional collapse.
Versioning
The versioning approach that we have designed is derived directly from the experience of the open source community, more specifically that of the JavaScript community’s “npm” registry, which is now both the largest and the fastest-growing open source repository in existence.
The expectation is for data to be published using Semantic Versioning (Preston-Werner 2014). A version number is composed of three dot-separated components: major, minor, and patch (e.g. “2.3.1”). Incrementing the patch component signals a small, backwards-compatible bug fix; incrementing the minor component indicates additive changes that do not break compatibility; and incrementing the major is reserved for cases that will most likely break dependents. The exact manner in which these are issued is not enforced; rather it is expected that publishers will use their discretion to apply semantic versioning in a manner that works well for their consumers and will wish to avoid the reputational cost involved in signalling greater reliability than is effectively the case. (Note that it is always possible for consumers to defend against errant publishers by always sticking to a static version.)
Articles that cite datasets can then do so flexibly by choosing their own policy as to referential stability, using the small expression language described in (npm 2015). A paper can describe itself as being reliant on a very specific version of the data by providing a strict version: “2.3.1”. Conversely, given the trust inherent in a specific community or discipline, or ascribed a specific source, authors can describe their work as being expected to be resilient to patch-level changes (“2.3.x”) or even minor-level changes (“2.x”). In the absence of versioning information, it is assumed that any version will do (this is typically best left to special cases, such as high-level discussions of a dataset).
This mechanism has the great advantage that it is socially and humanly enabling. It encourages publishers of data to signal the changes they make in a simple yet useful manner, and incites consumers to express precisely the level of confidence that they have in the generality of their usage of a dataset. The precedent of the open source community has shown diverse compatible and coexisting bodies of practice to emerge around this system.
The socially-enabling aspect is particularly important because we believe that going against the grain of the practices specific to certain disciplines or communities (or even projects) leads to people working around the system, eventually to the point of breaking it. As Mark Parsons stated in (NRC 2012): “Overall, we believe these issues can be largely resolved by, a well-defined versioning scheme, good tracking and documentation of the versions, and due diligence in archive and release practices. So, it is not a technical problem so much as a social problem demanding good professional practices”. The joint application of Semantic Versioning and semver matching is well-defined, self-documenting, and benefits from the experience of extensive practice (Preston-Werner 2014)(npm 2015).
Extensibility
The approach we have followed lends itself perfectly well to extensibility. Not only can any other part of schema.org be used, but other ontologies can be combined with it seamlessly. For instance, it would be perfectly possible to make use of the ontologies deployed as part of the “CSV on the Web” suite of specifications (Tennison, Kellogg, and W3C 2015).
Other extensions are equally possible, be they for domain-specific methodological provenance, publisher-specific access control, or embedded annotation metadata to capture the output of peer review. Extensibility is intrinsically layered into the system such that in no way can the addition of data interfere with expected information.
Conclusion
The implementation approach outlined in this paper builds upon our experience developing a Web-based format capable of fully addressing the needs of the scholarly publishing pipeline. Known as “Scholarly HTML” (Berjon and Ballesteros 2015), we are in the process of working with a W3C Community Group in order to further formalise it and to make sure it is usable by as broad a community as possible. Our ideas have also been informed by our experience trawling through thousands of publishing style guides (Standard Analytics 2015) in order to produce DS3 (Bogich and Ballesteros 2015).
The next steps we would like to take are to discuss this proposal with parties interested in data citations and use the feedback to refine this proposal until we are able to integrate it into Scholarly HTML.
It should be noted that the versioning method outlined in this paper is not yet ratified as part of schema.org; but it is openly discussed there and has received initially positive feedback. It serves to illustrate the value in open, community-based work.
We create software that both produces and consumes the sort of data described in this paper. Another step we plan on taking once feedback on this proposal has been received is to implement support for data citations in our articles as well as in our support for the production of landing pages.
The Web is both lasting and powerful; the methodologies inherent in Web-first publishing are well-suited to the needs of data citations.
Acknowledgements
Disclosure
References
- (Not) giving credit where credit is due: Citation of data sets, by Joan E. Sieber and Bruce E. Trumbo; published in issue 1, volume 1, of Science and Engineering Ethics, in , pages 11-20.
- Out of Cite, Out of Mind: The Current State of Practice, Policy, and Technology for the Citation of Data, by CODATA-ICSTI Task Group on Data Citation Standards and Practice; published in issue , volume 12, of Data Science Journal, on , pages CIDCR1-CIDCR75.
- Joint Declaration of Data Citation Principles, by Data Citation Synthesis Group; published by FORCE11, in (accessed on ).
- Achieving human and machine accessibility of cited data in scholarly publications, by Joan Starr, Eleni Castro, Mercè Crosas, Michel Dumontier, Robert R. Downs, Ruth Duerr, Laurel L. Haak, Melissa Haendel, Ivan Herman, Simon Hodson, Joe Hourclé, John Ernest Kratz, Jennifer Lin, Lars Holm Nielsen, Amy Nurnberger, Stefan Proell, Andreas Rauber, Simone Sacchi, Arthur Smith, Mike Taylor, and Tim Clark; published in volume 1 of PeerJ CompSci, on , page e1.
- Citing Data in Journal Articles using JATS, by Deborah Aleyne Lapeyre; published in .
- For Attribution — Developing Data Attribution and Citation Practices and Standards, by NRC; published in .
- Semantic Versioning 2.0.0, by Tom Preston-Werner; published in (accessed on ).
- semver — the semantic versioner for npm, by npm; published on (accessed on ).
- Scholarly HTML, by Robin Berjon and Sébastien Ballesteros; published in .
- SCHEMA, by schema.org; published by schema.org, in (accessed in ).
- DOCX Standard Scientific Style, by Tiffany Bogich and Sébastien Ballesteros; published in .
- First 1000 responses – most popular tools per research activity, by 101 Innovations; published on .
- Metadata Vocabulary for Tabular Data, by Jeni Tennison, Gregg Kellogg, and W3C; published on .
- Style Guide DB, by Standard Analytics; published in (accessed in ).